Reference no: EM132222472
Machine Learning Homework -
Written Questions -
1. Mean and Variance
The most familiar property of a distribution is its mean, or expected value, denoted by μ or E[X]. For discrete random variables (rv's), it is defined as E[X] 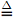 ∑x∈X xp(x), and for continuous rv's, it is defined as E[X] ∫xp(x)dx. The variance is a measure of the "spread" of a distribution, denoted by σ2. It is defined as var[X] E[(X - μ)2]. Show that σ2 = E[X2] - E[X]2, assume X is a discrete random variable. Hint: Expand the definition of variance.
∑x∈X xp(x), and for continuous rv's, it is defined as E[X] ∫xp(x)dx. The variance is a measure of the "spread" of a distribution, denoted by σ2. It is defined as var[X] E[(X - μ)2]. Show that σ2 = E[X2] - E[X]2, assume X is a discrete random variable. Hint: Expand the definition of variance.
2. Fitting a naive bayes spam filter by hand
Consider a Naive Bayes model for spam classification with the vocabulary V = "secret", "offer", "low", "price", "valued", "customer", "today", "dollar", "million", "sports", "is", "for", "play", "healthy", "pizza". We have the following example spam messages "million dollar offer", "secret offer today", "secret is secret" and normal messages, "low price for valued customer", "play secret sports today", "sports is healthy", "low price pizza". Give the MLEs for the following parameters: θspam, θsecret|spam, θsecret|non-spam, θsports|non-spam, θdollar|spam.
Machine Problem: Text Classification and Naive Bayes
1. Multinomial Naive Bayes Classifier
The goal of this assignment is for you to gain familiarity with the multinomial Naive Bayes classifier. Specifically, you will look into an existing Python-based implementation, fill out the missing code block, and explore an application of multinomial Naive Bayes to a multiclass text classification task.
In the homework package (HW1.tar.gz), you are provided with the starter code and a dataset. The code was written in Python 2.7 and numpy.
There are two data files in the package: positive.review and negative.review. They correspond to positive and negative book reviews. The text has been preprocessed so that each line contains a review document; each token (e.g., year:2) represents a word and its frequency in the document. The last token (e.g., #label#:negative) in each line indicates the polarity (label) of the document.
The starter code includes four files: linear classifier.py, multinomial naive bayes.py, run classifier.py, sentiment reader.py. The functionality of the files should be self-evident..
The file multinomial naive bayes.py currently has a missing code block. Search TODO in the file and you will find the missing block. Your task is to fill out the missing code. Upon successful completion of the code, you will run python run classifier.py and this will return the following results: Accuracy on training set: 0.972500, on test set: 0.835000.
Please submit: A report named report fiirstname lastname.pdf. Copy and paste the missing code block to the report.
Attachment:- Assignment Files.rar