Sequential File Organisation
The most necessary way to organise the collection of records in a file is to use sequential Organisation. Records of the file are stored in series by the primary key field values. They are accessible only in the order stored, i.e., in the primary key order. This type of file Organisation works well for tasks which require accessing nearly each record in a file, e.g., payroll. Let us see the benefits and drawbacks of it.
In a sequentially organised file data are written in a row when the file is created and must be accessed in a row when the file is later used for input (Figure ).
Figure: Structure of sequential file
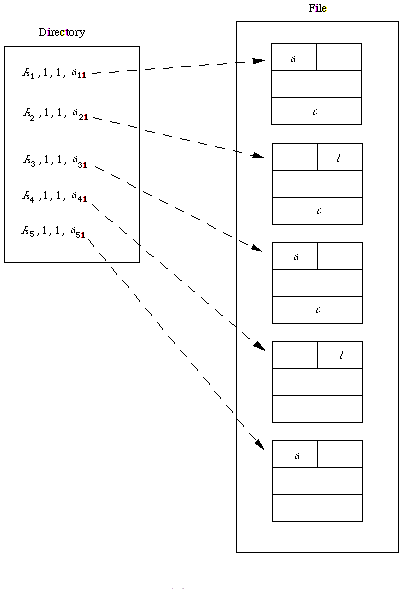
A sequential file keeps the records in the logical series of its primary key values. Sequential files are useless for random access, though, are suitable for sequential access. A sequential file can be kept on devices like magnetic tape that permit sequential access.
On an average, to search a record in a sequential file would need to look into half of the records of the file. though, if a sequential file is stored on a disk (remember disks support direct access of its blocks) with keyword stored independently from the rest of record, then only those disk blocks require to be read that have the desired record or records. This type of storage permits binary search on sequential file blocks, therefore, enhancing the speed of access.
Updating a sequential file usually makes a new file so that the record sequence on primary key is maintained. The update operation first copies the records till the record after which update is needed into the new file and then the updated record is put followed by the remains of records. Therefore method of updating a sequential file automatically makes a backup copy.
Additions in the sequential files are also handled in a same manner to update. Adding a record needs shifting of all records from the point of insertion to the end of file to make space for the new record. On the other hand deletion of a record needs a compression of the file space.
The basic benefit of sequential file is the sequential processing, as next record is simply accessible despite the absence of any data structure. Though, simple queries are time consuming for large files. A one update is expensive as new file must be formed, thus, to decrease the cost per update, all updates requests are sorted in the order of the sequential file. This update file is then used to update the sequential file in a one go. The file having the updates is sometimes referred to as a transaction file.
This process is known as the batch mode of updating. In this mode every record of master sequential file is checked for one or more possible updates by evaluating with the update information of transaction file. The records are saved to new master file in the sequential way. A record that needs multiple update is written only when all the updates have been presented on the record. A record that is to be deleted is not written to new master file. Therefore, a new updated master file will be formed from the transaction file and old master file.
Therefore, update insertion and deletion of records in a sequential file needs a new file creation. Can we decrease creation of this new file? Yes, it can simply be done if the original sequential file is formed with holes which are empty records spaces as shown in the Figure. Therefore, a reorganisation can be restricted to only a block that can be done very simply within the main memory. Therefore, holes increase the performance of sequential file deletion and insertion. This organisation also maintain a concept of overflow area, which can store the spilled over records if a block is complete. This method is also used in index sequential file organisation.