File System Interface and Implementation
The Nachos file system, as distributed, uses a single-level index allocation method for data allocation of files. In the current design, the file header (i-node) of a file can point to only NumDirect (its value is 30) data sectors. Therefore, the maximum size of a file is NumDirect*SectorSize, or 3840 bytes. In Laboratory 5, you have made Nachos files extendable. That is, one can increase the size of a file by writing more data to it. But, the maximum size of a file is still the same. You simply cannot put more data than 3840 bytes to a Nachos file. Programming Task: you are required to further change the Nachos file system to increase the maximum file size by using a two-level index allocation method similar to the UNIX file system. In particular, you will use the last entry of array dataSectors[] to store the sector number of the secondary indirect file header (i-node) when necessary. Figure ?? shows the file header structure for a file that is large enough to require two header sectors. Note that there is a new member required in the file header. The indirect member of the file header points to the secondary file header. Why are there are two links from the primary to the secondary header? The answer is because they are both needed at different times, and play different roles. For instance, when opening a file, the headers must be read from disk. The directory contains the sector number of the first header only, so that (primary) header must contain the sector number where the secondary file header can be found. However, once a file is open, and read and writes operations are being carried out, Nachos uses the file headers to determine where the data sectors reside on disk. As the Open File object can only point to one File Header object (the primary header), the primary
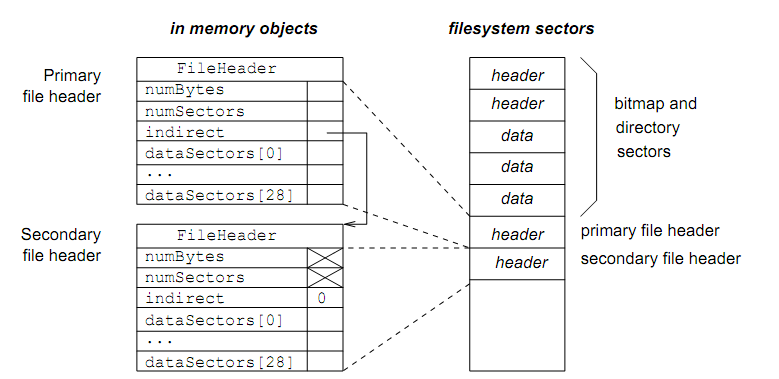
Figure: Two level file headers
Header must contain a pointer (a memory address, not a sector number) to the secondary file Header object.
So in summary, within a file header, dataSectors [NumDirect-1] is a "sector pointer" to the on-disk header, while indirect is an \object pointer" to an in-memory object.
Note also that numBytes and numSectors in the secondary header is not used and has no meaning.
The new definition of the data members of FileHeader should be as follows:
private:
int numBytes; // Number of bytes in the file
int numSectors; // Number of data sectors in // the file
FileHeader *indirect; // pointer to the indirect header
int dataSectors[NumDirect]; // Disk sector numbers for each
// data block in the file
Because we are adding a new data member, but the header must still fit into one sector, the definition of numDirect should change to:
#define NumDirect ((SectorSize - 3 * sizeof(int))/sizeof(int))
Here are a few other definitions that may be of use in coding the solution.
#define NumPrimary (NumDirect-1)
#define MaxFileSectors (NumPrimary+NumDirect)
#define MaxFileSize (MaxFileSectors * SectorSize)
If the sector size is 128 bytes, and integers occupy 4 bytes (the de- fault Nachos/Intel installation), then NumDirect = 29, NumPrimary = 28, MaxFileSectors = 57, and MaxFileSize = 7296. NumPrimary is the number of data sector elements that can be ad- dressed by the primary header. The elements are dataSectors[0] to dataSectors[NumPrimary-1]. In the primary header, the el- ement dataSectors[NumPrimary] will contain the sector number of the secondary header.
- The numBytes and numSectors members are only used in the primary header; they are ignored (wasted space) in the secondary header.
- The indirect member is always null in a secondary header.
- When the le header is written back to disk, the indirect eld will also be written. When it is subsequently read from disk, say when appending to a le, the indirect pointer value will be invalid as the object to which it pointed should have been deleted. The FetchFrom method will have to instantiate a new secondary header and assign its address to indirect.
- When a primary header is fetched from the le system, the presence of a secondary header can be determined by testing either numSectors>NumPrimary or indirect!=NULL (assum- ing indirect has been properly initialized).
- The secondary le header is not always present: if the size is small, the le system does not need to allocate the indirect i-node. The indirect i-node exists only if the size exceeds ((NumDirect-1) * SectorSize). The secondary le header is dynamically created only if and when it is needed.