Vliw Architecture
Superscalar architecture was designed to develop the speed of the scalar processor. But it has been realized that it is not easy to execute as we discussed previous. Following are some troubles faced in the superscalar architecture:
- It is required that additional hardware must be provided for hardware parallelism such as decoder, instruction registers, and arithmetic units, etc.
- Scheduling of instructions dynamically to decrease the pipeline delays and to keep all processing units busy is very complex.
Another way to improve the speed of the processor is to develop a sequence of instructions having no dependency and may need different resources, therefore avoiding resource conflicts. The idea is to join these independent instructions in a compact long word incorporating a lot of operations to be implemented simultaneously. That is why; this architecture is known as very long instruction word (VLIW) architecture. In fact, long instruction words take the opcodes of dissimilar instructions, which are dispatched to dissimilar functional units of the processor. In this way, all the operations to be implemented simultaneously by the functional units are synchronized in a VLIW instruction. The size of the VLIW instruction word can be in 100 of bits. VLIW instructions must be formed by compacting small instruction words of conventional program. The job of compaction in VLIW is complete by a compiler. The processor must have the sufficient resources to implement all the operations in VLIW word simultaneously.
For example, one VLIW instruction word is compacted to have store /load operation, floating point multiply, floating point addition, one branch, and one integer arithmetic as shown in Figure.

VLIW instruction word
A VLIW processor to support the above instruction word must have the functional components as shown in Figure given below. All the functions units have been incorporated according to the VLIW instruction word. All the elements in the processor share one common large register file.
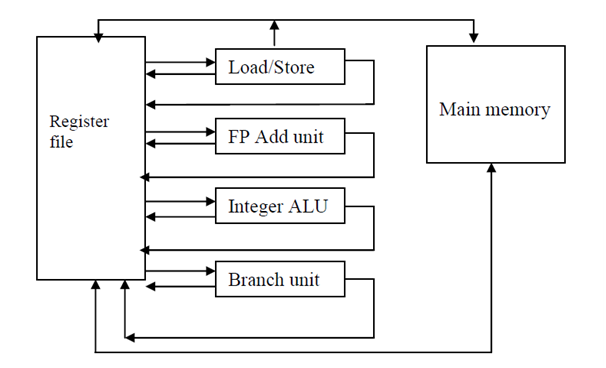
VLIW Processor
Parallelism in data movement and instructions should be totally specified at compile time. But scheduling of branch instructions at compile time is very complicated. To handle branch instructions, trace scheduling is adopted. Trace scheduling is based on the prediction of branch decisions with a few reliability at compile time. The prediction is based on some heuristics, hints given by the programmer or using profiles of some earlier program implementations.