Instruction Pipelines
As discussed previous, the stream of instructions in the instruction implementation cycle, can be realized through a pipeline where overlapped implementation of different operations are performed. The process of implenting the instruction involves the following main steps:
- Fetch the instruction by the main memory
- Decode the instruction
- Fetch the operand
- Implement the decoded instruction
These four steps become the candidates for phases for the pipeline, which we state as instruction pipeline (It is given in Figure).
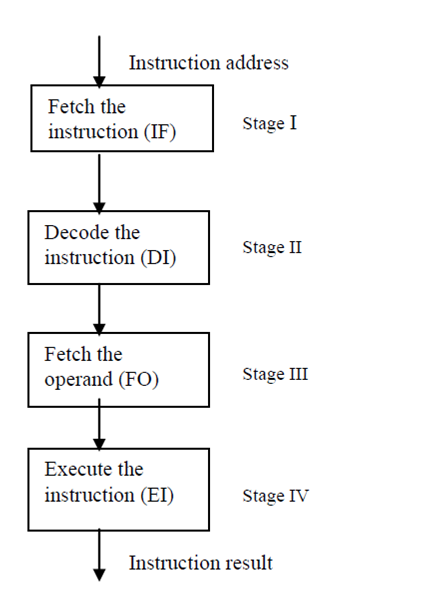
Figure: Instruction Pipeline
While, in the pipelined implementation, there is overlapped implementation of operations, the four phases of the instruction pipeline will work in the overlapped manner. Firstly, the instruction address is fetched from the memory to the first phase of the pipeline. The first phase fetches the instruction and provides its output to the second phase. Whereas, the second phase of the pipeline is decoding the instruction, the first phase gets another input and provides the next instruction. When the first instructions have been decoded in the second phase, then its output is fed to the third phase. When the third phase is fetching the operand for the first instruction, then the second phase gets the second instruction and the first phase gets input for another instruction and so on. In this manner, the pipeline is implementing the instruction in an overlapped way increasing the speed of execution and throughput.
The situation of these overlapped operations in the instruction pipeline can be demonstrated through the space-time diagram. In Figure, firstly we show the space-time diagram for non-overlapped implementation in a sequential environment and then for the overlapped pipelined environment. It is clear from the two diagrams that in non-overlapped implementation, results are achieved only after 4 cycles while in overlapped pipelined implementation, after 4 cycles, we are receiving output after every cycle. Soon in the instruction pipeline, the instruction cycle has been deduced to ¼ of the sequential implementation.
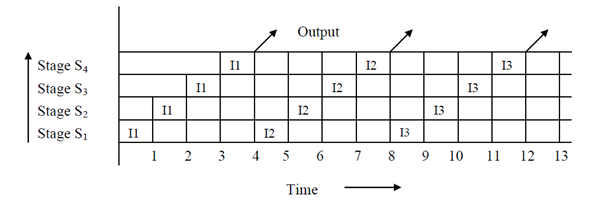
Space-time diagram for Non-pipelined Processor
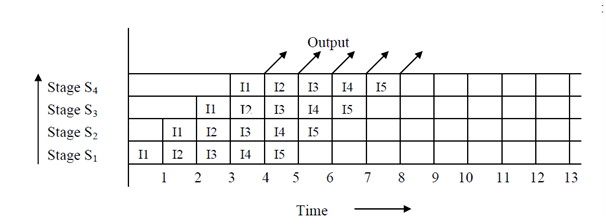
Space-time diagram for Overlapped Instruction pipelined Processor