Reference no: EM133083105
732A55 Neural Networks and Learning Systems
Question 1: Classify the following learning methods as supervised (S) or unsupervised (U):
• k-Nearest Neighbors
• Support Vector Machines
• AdaBoost
• Principal Component Analysis
• Multi-layer Perceptron (Neural Network)
• Mixture of Gaussian Clustering
Question 2: How is the accuracy of a classifier calculated?
Question 3: Why are the following two functions not useful in the hidden layers in a back- propagation neural network?
• y = s
• y = sign(s)
Question 4. What is described by the first eigenvector of the data covariance matrix (if the data have zero mean)?
Question 5. What assumption is made about the distributions of the two classes in linear dis- criminant analysis?
Question 6. Suppose that you know the Q-function values for a certain state. How do you determine the V-value for that state?
Question 7. What is the purpose with a momentum term in gradient descent?
Question 8. In which kind of learning tasks is linear units more useful than sigmoid activation functions in the output layer of a multi-layer neural network?
Question 9. Explain the purpose with the so-called slack variables in Support Vector Machines.
Question 10. All the weights one layer in a neural network kan be described as a matrix W. Describe an important property of this matrix for a convolutional layer in a CNN.
Part 2
Question 11. What are the two (main) differences between supervised and reinforcement learning?
Question 12. Describe briefly the two steps that are iterated in the k-means clustering algorithm.
Question 13. Consider the following explicit non-linear mapping of the input data x = (x1, x2)T :
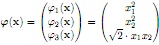
Kernel methods use kernel functions to avoid explicit mappings and calculations in higher-dimensional feature spaces as above.
• What does a kernel function κ(xi, xj) calculate?
• Find the expression for the kernel function that corresponds to the mapping above.
Question 14: ReLU activation functions are more and more used in neural networks instead of the tanh activation function. Draw both activation functions and give a) an advantage of the ReLU function compared to the tanh function. b) a disadvantage of the ReLU function compared to the tanh function.
Question 15: In SVM, a cost function is minimized under the following constraint:
di(wT xi) + b ≥ 1.
What is the cost function being minimized, and for which xi are the constraint forfilled with equality?
Part 3
(N.B. Write all answers in this part on separate sheets of papers! Don't
answer more that one question on each sheet!)
Question 16. The convolution of a 2D image f (x, y) and a kernel h(x, y) is defined as
g(x, y) = (f*h)(x, y) = Σα=-∞Σβ=-∞ f(α, β)h(x - α, y - β).
a) Perform the convolution below, i.e. calculate the image C. All values outside the image array A are equal to zero. In the arrays A and B, the respective number written in bold face is at position (x, y) = (0, 0). Note that C is only a part of the convolution result.
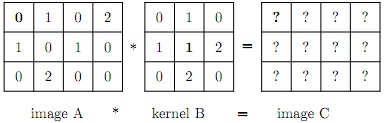
b) In practice, when implementing convolution, e.g. like convolve(A,B), no part of the kernel can be placed outside the image. Consequently, the resulting 2D array has size 1 × 2 and is equal to the central part of the image array C above. By extending the image array A to a new image array AA in a suitable way, convolve(AA,B) will be equal to C. Give the image array AA.
c) A CNN consists of N complex layers. Each complex layer consists of a con- volution with a 3 × 3 kernel, a sigmoid activation, and a max pooling layer with stride 2 in each dimension. The input image is 512 × 512. Compute the (spatial) size of the layer after the first and second pooling. When is the image of size 1 × 1, i.e. what is the maximum value for N?
Question 17: We want to classify some data using the network below. There are three input parameters and two output classes. The network is trained using standard error back-propagation, i.e. the square error should be minimized using gradient search. The network has one hidden layer and one output layer, see figure.
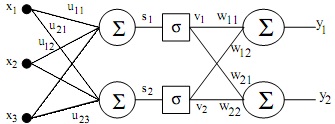
A team of engineers implemented the above neural network, but forgot the bias weight and the activation function. So, without knowing it, they used σ(x) = x as activation function.
a) Derive the update expressions for the weights in both layers.
b) Explain the restrictions, if any, that are imposed upon the decision boundaries because of the nonexisting bias weights and activation functions.
Question 18. You have the following data:
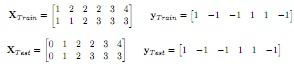
where XT rain & XT est contain six 2d-samples (one per column), and yT rain & yT est contain classification labels for the corresponding samples. We have performed two iterations of AdaBoost using 'decision stumps' as weak classifiers on the data XT rain. We calculated the following weights (d), classification labels (c) and α for each weak classifier:
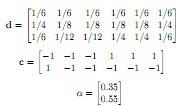
a) Perform the third AdaBoost iteration on the data XT rain using the labels y and 'decision stumps' as weak classifiers. Calculate d4, c3 and α3
b)Apply the strong classifier on the data XT rain and the data XT est. What is the accuracy for the XT rain data and the XT est respectively?
c) Will we be able to achieve an accuracy of 100 % for the test data with more iterations? Motivate your answer!
Question 19: Figure shows a reinforcement learning problem with eight states in which the valid actions are right and up. State S8 is terminal and moving into it results in a reward of 5. Moving into state S6 results in a reward of -1. All remaining states result in a reward of 0.
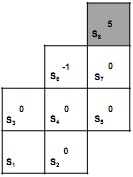
Figure 1: All possible states and rewards
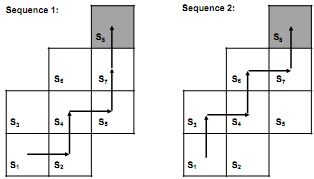
Figure 2: Sequences of action
Show how the Q-values are modified by the Q-learning algorithm if sequence 1 is used once, followed by sequence 2, and then a final use of sequence 1.
Give the results as a function of γ and α. All Q-values are initialized at 0.