Reference no: EM131105458
10-701 Midterm Exam, Spring 2005
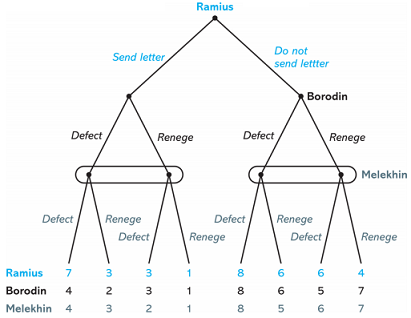
1. Big Picture
Following the example given, add 10 edges to Figure 1 relating the pair of algorithms. Each edge should be labeled with one characteristic the methods share, and one difference. These labels should be short and address basic concepts, such as types of learning problems, loss functions, and hypothesis spaces.
2. Short Questions
(a) Briefly describe the difference between a maximum likelihood hypothesis and a maximum a posteriori hypothesis.
(b) Consider a naive Bayes classifier with 3 boolean input variables, X1, X2 and X3, and one boolean output, Y.
- How many parameters must be estimated to train such a naive Bayes classifier? (you need not list them unless you wish to, just give the total)
- How many parameters would have to be estimated to learn the above classifier if we do not make the naive Bayes conditional independence assumption?
True or False? If true, explain why in at most two sentences. If false, explain why or give a brief counterexample in at most two sentences.
- (True or False?) The error of a hypothesis measured over its training set provides a pessimistically biased estimate of the true error of the hypothesis.
- (True or False?) If you are given m data points, and use half for training and half for testing, the difference between training error and test error decreases as m increases.
- (True or False?) Overfitting is more likely when the set of training data is small.
- (True or False?) Overfitting is more likely when the hypothesis space is small.
3. Learning Algorithms
Consider learning a target function of the form f: R2 → {A, B, C} that is, a function with 3 discrete values defined over the 2-dimensional plane. Consider the following learning algorithms:
- Decision trees
- Logistic regression
- Support Vector Machine
- 1-nearest neighbor
Note each of these algorithms can be used to learn our target function f, though doing so might require a common extension (e.g., in the case of decision trees, we need to utilize the usual method for handling real-valued input attributes).
For each of these algorithms,
A. Describe any assumptions you are making about the variant of the algorithm you would use.
B. Draw in the decision surface that would be learned given this training data (and describing any ambiguities in your decision surface).
C. Circle any examples that would be misclassified in a leave-one-out evaluation of this algorithm with this data. That is, if you were to repeatedly train on n-1 of these examples, and use the learned classifier to label the left out example, will it be misclassified?
4. Decision Trees
NASA wants to be able to discriminate between Martians (M) and Humans (H) based on the following characteristics: Green ∈ {N, Y }, Legs ∈ {2, 3}, Height ∈ {S, T }, Smelly ∈ {N, Y }.
Our available training data is as follows:
|
|
Species
|
Green
|
Legs
|
Height
|
Smelly
|
|
1)
|
M
|
N
|
3
|
S
|
Y
|
|
2)
|
M
|
Y
|
2
|
T
|
N
|
|
3)
|
M
|
Y
|
3
|
T
|
N
|
|
4)
|
M
|
N
|
2
|
S
|
Y
|
|
5)
|
M
|
Y
|
3
|
T
|
N
|
|
6)
|
H
|
N
|
2
|
T
|
Y
|
|
7)
|
H
|
N
|
2
|
S
|
N
|
|
8)
|
H
|
N
|
2
|
T
|
N
|
|
9)
|
H
|
Y
|
2
|
S
|
N
|
|
10)
|
H
|
N
|
2
|
T
|
Y
|
a) Greedily learn a decision tree using the ID3 algorithm and draw the tree.
b) i) Write the learned concept for Martian as a set of conjunctive rules (e.g., if (green=Y and legs=2 and height=T and smelly=N), then Martian; else if ... then Martian; ...; else Human).
ii) The solution of part b)i) above uses up to 4 attributes in each conjunction. Find a set of conjunctive rules using only 2 attributes per conjunction that still results in zero error in the training set. Can this simpler hypothesis be represented by a decision tree of depth 2? Justify
5. Loss functions and support vector machines
relationship between ridge regression and the maximum a posteriori (MAP) approximation for Bayesian learning in a particular probabilistic model. In this question, you will explore this relationship further, finally obtaining a relationship between SVM regression and MAP estimation.
(a) Ridge regression usually optimizes the squared (L2) norm:
W^L2 = arg minw j=1ΣN(tj - Σiwihi(xj))2 + λΣiwi2. (1)
The L2 norm minimizes the squared residual (tj -Σi wihi(xj))2, thus significantly weighing outlier points. (An outlier is a data point that falls far away from the prediction Σi wihi(xj).) An alternative that is less susceptible to outliers is to minimize the "sum of absolute values" (L1) norm:
W^L1 = arg minw j=1ΣN|tj - Σiwihi(xj)| + λΣiwi2. (2)
(i) Plot a sketch of the L1 loss function, do not include the regularization term in your plot. (The x-axis should be the residual tj - Σi wihi(xj) and the y-axis is the loss function.)
(ii) Give an example of a case where outliers can hurt a learning algorithm.
(iii) Why do you think L1 is less susceptible to outliers than L2?
(vi) Are outliers always bad and we should always ignore them? Why? (Give one short reason for ignoring outliers, and one short reason against.)
(v) As with ridge regression in Equation 1, the regularized L1 regression in Equation 2 can also be viewed a MAP estimator. Explain why by describing the prior P(w) and the likelihood function P(t| x, w) for this Bayesian learning problem.
P(x) = (1/2b)e-|x-µ|/b.
(b) As mentioned in class, SVM regression is a margin-based regression algorithm that takes two parameters, ∈ > 0 and C ≥ 0, as input. In SVM regression, there is no penalty for points that are within ∈ of the hyperplane. Points that are further than ∈ are penalized using the hinge loss. Formally, the SVM regression QP is:
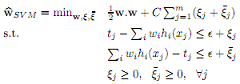
(i) Plot a sketch of the loss function function used by SVM regression. Again, the x-axis should be the residual tj - Σiwihi(xj) and the y-axis the loss function. However, do not include the ½w.w term in this plot of the loss function.
(ii) Compared to L2 and L1, how do you think SVM regression will behave in the presence of outliers?
(iii) SVM regression can also be view as a MAP estimator. What is the prior and the likelihood function for this case?
6. Learning Theory
This question asks you to consider the relationship between the VC dimension of a hypothesis space H and the number of queries the learner must make (in the worst case) to assure that it exactly learns an arbitrary target concept in H.
More precisely, we have a learner with a hypothesis space H containing hypotheses of the form h: X → {0, 1}. The target function c: X → {0, 1} is one of the hypotheses in H. Training examples are generated by the learner posing a query instance xi ∈ X, and the teacher then providing its label c(xi). The learner continues posing query instances until it has determined exactly which one of its hypothesis in H is the target concept c.
Show that in the worst case (i.e., if an adversary gets to choose c ∈ H based on the learner's queries thus far, and wishes to maximize the number of queries), then the number of queries needed by the learner will be at least VC(H), the VC dimension of H. Put more formally, let MinQueries(c, H) be the minimum number of queries needed to guarantee learning target concept c exactly, when considering hypothesis space H. We are interested in the worst case number of queries, W orstQ(H), where
W orstQ(H) = maxc∈H[MinQueries(c, H)]
You are being asked to prove that
WorstQ(H) ≥ V C(H)
You will break this down into two steps:
(a) Consider the largest subset of instances S ⊂ X that can be shattered by H. Show that regardless of its learning algorithm, in the worst case the learner will be forced to pose each instance x ∈ S as a separate query.
(b) Use the above to argue that W orstQ(H) ≥ V C(H).
(c) Is there a better case? In other words, if the learner knows that a friend (not an adversary) will be choosing c ∈ H, and that the friend wishes to minimize the number of learning queries, is it possible for the friend to choose a c that allows the learner to avoid querying all of the points in S? More formally, if we define
BestQ(H) = minc∈H[MinQueries(c, H)]
then is the following statement true or false?
BestQ(H) ≥ V C(H)
Justify your answer.
7. Extra credit question: Bias-Variance trade-off
Suppose you want to learn a function y = f(x) + ε, where ε is an independent zero-mean noise variable. In class, you learned that the expected squared error of a learned hypothesis fˆ(x) at any specific point x0 can be decomposed into three parts:
Err(x0) = E[(Y - fˆ(x0))2 | x = x0],
= σ2 + [f(x0) - E(fˆ(x0))]2 + E[( ˆf(x0) - E(fˆ(x0)))2],
= Irreducible Error + Bias2 + Variance.
where the expected value is taken over different training data sets.
For this question, we'll assume the target function to be learned is f(x) = x and that ε is a zero-mean Gaussian random variable with variance σ2. We'll also assume the available training data consists of a fixed set of n equally spaced data points in x ∈ [a, b], and therefore the only randomness in different draws of training data arises from the randomness in the values of ε. Below you will consider approximating f(x) using different types of ˆf(x) functions. In each case, assume fˆ(x) is trained using least-squares regression based on this data.
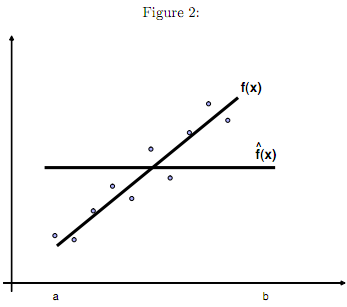
(a) Suppose the learner considers only constant functions as possible hypotheses, i.e., fˆ(x) = w0. (see figure 2).
(i) Write the result of regression fˆ(x) as a function of the input data {y1, . . . , yn}.
(ii) What is the expected value of our estimator, E[fˆ(x)], where the expectation is taken over possible data sets?
(iii) Provide an upper bound over x0 ∈ [a, b] for the value of the bias term:
maxx0∈[a,b][f(x0) - E(fˆ(x0))]2.
(iv) What is the variance term:
E[(fˆ(x0) - E(fˆ(x0)))2]?
Hint: The variance is the same for all x0.
(b) Now, suppose that fˆ(x) is represented by two step functions: fˆ1(x) takes value w1 for x ∈ [a, a+b/2 ], and fˆ2(x) takes value w2 for x ∈ (a+b/2 , b].
(i) Provide an upper bound over x0 ∈ [a, b] for the value of the bias term.
(ii) What is the variance term?
(c) Finally, suppose that fˆ(x) is represented by m ≤ n equally spaced step functions.
(i) Provide an upper bound over x0 ∈ [a, b] for the value of the bias term.
(ii) What is the variance term?
(iii) Based on this analysis, what is the optimal number of step functions for learning f(x) in this problem setting; that is, what number of step functions produces the smallest expected squared error in the learned hypothesis? (Your answer should be an equation in terms of n, a, b, σ2.)