Reference no: EM13873046
Problem 1: K-means clustering
For this question you need to refer to the k-means clustering algorithm in the Course Slides posted on Blackboard.
|
Point
|
x
|
y
|
|
1
|
1.0
|
1.0
|
|
2
|
1.5
|
2.0
|
|
3
|
3.0
|
4.0
|
|
4
|
5.0
|
7.0
|
|
5
|
3.5
|
5.0
|
|
6
|
4.5
|
5.0
|
|
7
|
3.5
|
4.5
|
Assume we have the above dataset that shows 7 points in a 2-dimensional space, with x coordinates shown in the x column, and y coordinates shown in the y column. Assuming the number of clusters is set to 2 (i.e., k=2), and distances among points are measured by Euclidean distance. Based on observation, a good choice of the initial centroids (cluster centers) are point 1 (1.0, 1.0) and point 4 (5.0, 7.0) (these two points are relatively further away from each other). Your job is to run the k-means algorithm and answer the following questions.
(i) After the initial centroids are assigned (shown above), the first step in a clustering process is to check the rest of the points and assign them to one of the two clusters. Here we assume that the centroid remain unchanged during the first round (iteration).
Determine cluster memberships (which points belong to Cluster 1 and which belong to Cluster 2) for each of these 7 points after the first iteration. Show intermediate results how you obtain the solution.
(ii) Based on the results obtained from step (i), recalculate centroids (the mean vectors) for the two clusters. Then recalculate the distance from each point to its centroid. Show your results. Are there any points need to change their cluster memberships? If so, what are these points?
(iii) Continue the process shown in step (ii) for another iteration. Do you observe any changes in cluster memberships? If so, what are these points? If not, will there be further changes if we continue the process with more iterations?
Notes:
• It would be easier to solve the problem if you can draw a picture and show changes of centroids on a 2-dimensional system.
• Since this is a tiny dataset, the entire process can be computed by hand.
Problem 2: Logic
(i) Look at the following sentences written in first-order logic. Explain these sentences in plain English. Based on the definitions on validity and satisfiability, are these statements valid? If not, are they satisfiable? [20 points]
∀x ∃y Loves(x, y) ⇔∃x ∀y Loves(x, y)
∀x Loves(x, movie) ⇔ ¬∃x ¬Loves(x, movie)
∃x Loves(x, movie) ⇔ ¬∀x ¬Loves(x, movie)
¬∀x ¬ Loves(x, movie) ⇔ ∀x Loves(x, movie)
(ii) Based on our discussion on refutation resolution, given the following premises:
Father(A, B) Alive(A)
∀x∀y Father(x, y) ⇒ Parent(x, y)
∀x∀y (Parent(x, y) ∧ Alive(x)) ⇒ Older(x, y) Prove the following: Older(A, B)
Note: this simple question can also be proved by forward/backward reasoning. However you are required to use refutation resolution. [20 points]
Problem 3: Fuzzy Logic
The following fuzzy function was used to calculate membership values for the set healthy. A membership value of 1 is healthy; a membership value of 0 is not healthy; a membership value between 0 and 1 is the degree of membership in the healthy set.
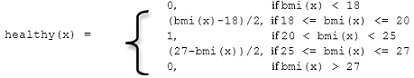
BMI values that range from 20 to 25 are members of the healthy set (1). BMI values greater than 27 or less than 18 are not members of the healthy set (0). BMI values close to the healthy range (20 to 25) are a value between 0 and 1. For example, a BMI of 19.6 is 0.8 degree of membership in the healthy set.
(i) Draw the graphic for the healthy set, representing the values, healthy and unhealthy.
(ii) What is the degree of membership to the fuzzy set healthy of person B who has a BMI of 26.2? And to the fuzzy set unhealthy?
(iii) In this example, is it possible that the total degree of membership (summation of degrees of membership in different sets) exceeds 1? Why or why not?