The Google File System - Logic Introduction
The definition of Computer says that it is an electronic device whichhas the ability to store, retrieve and process the data. In general the data would be process and then stored. Whenever required the necessary data that is already stored will be retrieved and then processed. So it is clear that storing of the data plays a very key role. Normally the information placed in a storage area which is a large body of data. Here in this context of storage area it is highly difficult task to find out where exactly one piece of information resides. So dividing the data into pieces and giving name to each piece makes it easier to find or locate them whenever required. A structure and logic will be maintained to manage groups of information and the names is called "File System". So a file system is used to control how data is stored and retrieved when required. Numerous file systems exists which are unique in their own structures, logics, security, flexibility, size and speed of accessibility.
The word file system is also referred as a partition or disk which is used to store the files.A partition or disk can be used as a particular file system based on the requirement. Before doing so, it needs to be initialized and the data structures need to be written on the disk.
Different Types of the File Systems
Each and every individual operating system is capable of organizing data internally in a unique way which is done with the help of File System. The type of file system determines how data is accessed and also the level of accessibility available to users.The type of the file system depends on the Operating Systems and below is some of the different file systems:
Windows File Systems: Microsoft Windows uses couple of file systems FAT (File Allocation Table) and NTFS (New Technology File System). NTFS has been developed to use in the NT Kernel and is being used widely now. If the disk size is over 32GB, then NTFS would be the default file system in Windows operating system.NTFS supports much larger disk storages as it uses 48 and 64 bit values to reference the files.
Mac OS File System: Previously Mac used HFS (Hierarchical File System) file system currently which has been upgraded to HFS+ file system. All the Apple products including iPhone, iPad and iPod uses the same file system. In this file system, volumes are divided into sectors which are usually 512 bytes and these sectors are grouped into allocation blocks.
Linux File Systems: As the Linux is the open source kernel there is huge number of file systems existing and there are certain file systems which are more popular. Ext2, Ext3, Ext4 are the series of file systems in which Ext3 makes use of transactional file operators with journal and Ext4 is with extended support of optimized file allocation information and attributes.XFS, JFS andReiserFS are some other popular file systems developed foe Linux operating system.
UNIX File Systems:UFS (Unix File System) is widely used file system in UNIX operating system which is also known as FFS (Fast File System). As of now all the Unix- family OS uses the UFS and it is also the major file system of BSD OS and Sun Solaris.
Google File System
Introduction: Soon after opening a web browser, the most common thing that most of us does is to navigate to the Google search home page. This is enough to describe the amount of load that Google bears each and every second. There will be millions and millions of requests coming and the results were displayed within few micro seconds. To handle the rapidly growing demands of Google data processing, the Google File System (GFS) has been designed and implemented.
GFS is a scalable distributed file system for large distributed data-intensive applications.GFS delivers high collective performance to a large number of clients as it runs on inexpensive hardware. Scalability, Performance, Reliability and Availability are the main goals of GFS which are derived from the previous versions of the distributed file systems. But the design structure of GFS is a bit different where the current workload and technical environment have been considered. There are some defects in the existing design and so they have been addressed in GFS. Some of the defects in the previous distributed file systems are as below:
Ø As there is huge number of components deployed, for sure there will be certain components that are non-functional at any given point of time.
Ø It is not so easy to maintain billions of files that are KB sized even though the file system supports it.
Ø Most of the times, files are altered by appending new data rather than overwriting existing data.
GFS Architecture
Below diagram represent the model of the GFS. Each GFS cluster consists of single master server and multiple chunk servers. Multiple servers can access the GFS at any given point of time.
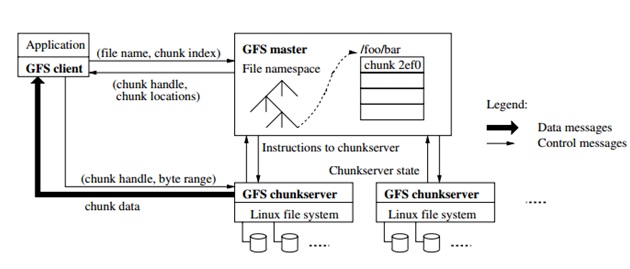
As long as the machine resources allows both the chunk server and the client can be run on the same machine. Files are divided into fixed-size chunks. Each chunk is identified by an absolute and globally unique 64 bit chunk allocated by the master at the time of creation of the chunk. To achieve reliability every chunk is replicated on multiple chunk server and by default three replicas are stored.
All the file system metadata is maintained by the master which includes namespace, chunk locations, and information related to access control. Garbage collection, lease management, migration between chunks servers are also maintained nu the master. To collect the state of each chunk, master periodically communicates with each server and gives instructions.
Write Control and Data Flow
The below figure illustrates the process of write control of the data flow:
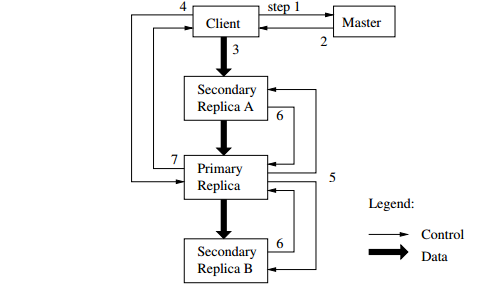
1. Client asks master for the chunk server where the current lease is hold. Master grants one chunk to replica if no one has a lease.
2. Now the master replies with the primary identity and the location of the replicas. Client saves this data doe the future purpose and needs to contact master only after the primary becomes unreachable.
3. Client sends data to all replicas in any order.
4. Once all the replicas confirm on the receiving of the data, then the client sends a write request to primary. Successive serial numbers will be assigned by the primary to all the mutations.
5. Now the write request will be forwarded by the primary to all the secondary replicas. Even the secondary assigns the same serial numbers.
6. All secondary replicas confirms back to the primary saying that the action has been completed.
7. After this the primary replies to the client.
GFS client code breaks down the application into multiple write operations if the write application is large.
Limitations and Solutions:
Frequent component failure is the most commonly faced challenge where, quantity and quality of components make this problem more custom. Some of the challenges faced are as below:
High Availability: In a GFS that comprises some thousands of servers, there will be some unavailable servers all the time and to deal with those servers system was made as highly available by implementing fast recoveries and fast replication.
Data Integrity: Disk failures are also quite common which in turn causes data corruption. Recovering from corrupt date using other chunk replicas can be done but by comparing replicas it would be impractical to detect corruption. So each and every chunk server needs to be independently verified by maintaining copy of own checksums.
Diagnostic Tools: Maintaining logs helps in detecting the problem, debugging into it and finally fixing with minimum cost. As the logs are written in a sequential manner the performance impact of logging is minimum. All the most recent logs are also stored in the memory and will be made available for the continuous improvement.
Conclusion
While supporting large-scale data processing workloads GFS play a vital role in providing the quality.GFS delivers fault tolerance by continuous monitoring, duplicating critical data, and fast and involuntary recovery. To simultaneous readers and writers GFS design delivers high aggregate throughput. This is achieved by separating the file system control. GFS is widely used as a storage platform for research and development as it meets the storage needs and became an important tool that enabled to continue to attack problems and innovate.